

Scientific intelligence platform for AI-powered data management and workflow automation



Scientific intelligence platform for AI-powered data management and workflow automation
Once step 3 is completed, and the effect size is specified, you can move onto step 4, which is to compute the sample size or power for the study.
The most common situation is that you want to find the required sample size for a given power. In general, increasing sample size is associated with an increase in power.
Traditionally, in clinical trials, 80% power would have been chosen. This would give a 1 in 5 chance of not rejecting the null hypothesis when indeed it is true. Choosing a power of 80% runs a reasonable risk of an underpowered study, however, if the true effect is smaller than initially thought, or other parameters are inaccurately estimated.More recently statisticians such as Steven Julious have recommended aiming for 90% power, which slightly mitigates the risk of an underpowered study, as even if there are dropouts, or the standard deviation or other parameters are more extreme than anticipated, there will still be greater than 80% power. In addition, two confirmatory trials are usually required for regulatory approval and two trials with 90% power will have at least 80% power to find a significant effect in both studies based on the two trials’ outcomes being independent and thus the combined power being equal to 0.9 squared i.e. 81%.
You may also want to consider some additional adjustments to the sample size to deal with known complications that may occur in a study. The most common adjustment is for dropout with the most common adjustment being dividing the original sample size estimation by one minus proportion expected to dropout during the course of the study. This is illustrated in the example below.
Certain sample size determination methods allow for more complex dropout patterns such as those used in time to event analyses and these cases dropout will be treated as if it were an unknown parameter from Step 2. Other adjustments can similarly be made for issues such as the treatment crossover or the effect of delayed accrual.
Sometimes, however, the sample size may be constrained by study costs such as the drug manufacture cost or the size of the available population. This may be particularly relevant in academic settings with smaller budgets. In this case, it can be useful to know what the power would be, given the assumptions from steps 2 and 3, and the available sample size. This will establish how viable the study is, and how likely it is to give useful conclusions for the current study.
An example from Sakpal (2010) will now be examined. “An active-controlled randomized trial proposes to assess the effectiveness of Drug A in reducing pain. A previous study showed that Drug A can reduce pain score by 5 points from baseline to week 24 with a standard deviation (σ) of 1.195. A clinically important difference of 0.5 as compared to active drug is considered to be acceptable.”
For this test we would like to find the sample size required for 80% power, with a two-sided 5% level of significance.
The formula required is:
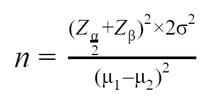
Where n = required sample size in each group, μ1is the mean change in pain score from baseline to week 24 in Drug A = 5, μ2is the mean change in pain score from baseline to week 24 in Drug B = 4.5, the clinically important difference μ1-μ2= 0.5, σ is the standard deviation = 1.195.
Zα2is the standard normal z-value for a significance level α = 0.05, which is 1.196. Zβis the standard normal z-value for the power of 80%, which is 0.84.
Using the formula above, the required sample size per group is 90, and thus the total sample size required is 180.
This calculation can also be completed using the nQuery software, by selecting the “Two Sample Z-test” table, and entering the parameters above. The calculation again shows that a sample size of 90 is required in each group.
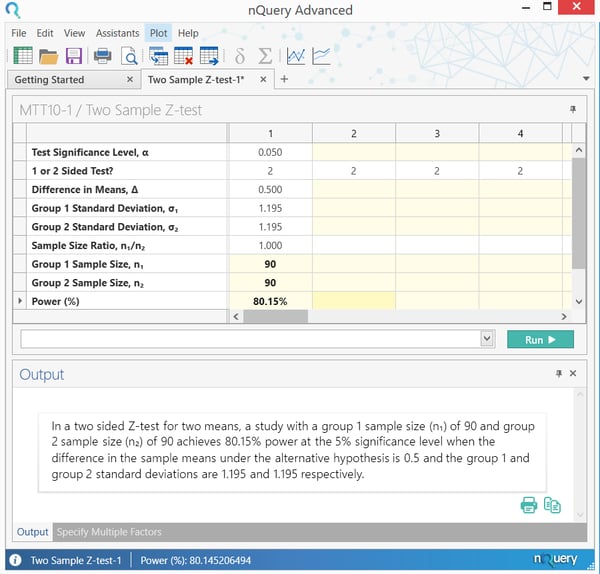
In addition, we will add an assumed total dropout of 10% during the course of the study. To calculate the adjusted sample size, we divide the total expected sample size by one minus the proportion expected to dropout (0.10 in this case). We thus divide 180 by 0.9 to give a sample size adjusted for dropout of 200 in this study.
Once steps 1 to 4 have been completed, and the appropriate sample size or relevant power has been found, you can move onto step 5 which is to explore the uncertainty in your sample size design.
The unknown parameters and effect size that have been defined in steps 2 and 3 are just that - estimates. It is not known what the true value of these parameters should be. If all these parameters were known, there would be no need to run the clinical trial! If the parameters are inaccurate, we risk the possibility of underpowering the study and not having a large enough sample size to find the effect size or we may overpower and subject too many people to what may be an ineffective treatment.
Traditionally, this uncertainty would have been explored primarily using sensitivity analysis. A sensitivity analysis is a part of planning a clinical trial that is easily forgotten but is extremely important for regulatory purposes and publication in peer-reviewed journals. It involves analyzing what effect changing the assumptions from parts 2, 3 and 4 would have on the sample size or power in the particular sample size or power calculation. This is important as it helps in understanding the robustness of the sample size estimate and dispels the common overconfidence in that initial estimate.
Some parameters have a large degree of uncertainty about them. For example, the intra-cluster correlation is often very uncertain when based on the literature or a pilot study, and so it’s useful to look at a large range of values for that parameter to see what effect that has on the resulting sample size. Moreover, some analysis parameters will have a disproportionate effect on the final sample size, and therefore seeing what effect even minor changes in those parameters would have on the final sample size is very important.
When conducting a sensitivity analysis, a choice has to be made over how many scenarios will be explored and what range of values should be used. The number of scenarios is usually based on the amount of uncertainty and sensitivity to changes and when these are larger, more scenarios should be explored. The range of values is usually based on a combination of the evidence, the clinical relevance of different values and the distributional characteristics of the parameter. For example, it would be common to base the overall range on the range of values seen for a parameter seen across a wide range of studies or to base it on the hypothetical 95% confidence interval for the parameter based on previous data or a pilot study. For effect size, clinically relevant values will tend to be an important consideration for which range of values to consider.
However, it is important to note that there is no set rules for which scenarios should be considered for a sensitivity analysis and thus sufficient consideration and consultation should be used to define the breadth and depth of sensitivity suitable for the sample size determination in your study.
A sensitivity analysis for the example above is shown below. Here, the standard deviation in the group receiving the new treatment is varied, to assess the effect on the sample size required in that group. The sample size in the control group remains at 90, and we are always aiming for 90% power. The plot shows that as the standard deviation increases, the sample size required increases dramatically. If the standard deviation is underestimated, a larger sample size is required to reach 80% power, and thus the trial will be under powered.
For σ= 1.5, 1 = 142, while for σ= 2.0, 1 = 253. This shows the importance of estimating the standard deviation as accurately as possible in the planning stages, as it has such a large impact on sample size and thus power.
Though sensitivity analysis provides a nice overview of the effect of varying the effect size or other analysis parameters, it does not present the full picture. It usually only involves assessing a small number of potential alternative scenarios, with no set official rules for choosing scenarios and how to pick between them.
A method often suggested to combat this problem is Bayesian Assurance. Although this method is Bayesian by nature, it is used as a complement to frequentist sample size determination.
Assurance, which is sometimes called “Bayesian power” is the unconditional probability of significance, given a prior or prior over some particular set of parameters in the calculation. These parameters are the same parameters detailed in steps 2 and 3 above.
In practical terms, assurance is the expectation of the power over all potential values for the prior distribution for the effect size (or other parameter). Rather than expressing the effect size as a single value, it is expressed as a mean (the value the effect size is most likely to be - usually the value used in the traditional power calculation) and a standard deviation (expressing your uncertainty about that value). If the power is then averaged out over this whole prior, the result is the assurance. This is often framed as the “true probability of success”, “Bayesian Power” or “unconditional power” of a trial.
In a sensitivity analysis, a number of scenarios are chosen by the researcher, and assessed individually for power of sample size. This gives a clear indication of the merits of the individual highlighted cases, but no information on other scenarios. With assurance, the average power over all plausible values is determined by assigning a prior to one or more parameters. This provides a summary statistic for the effect of parameter uncertainty, but less information on specific scenarios.
Overall, assurance allows researchers to take a formal approach to accounting for parameter uncertainty in sample size determination and thus create an opportunity to open a dialog on this issue during the sample size determination process. The definition of the prior distribution also allows an opportunity to formally engage with previous studies and expert opinion via approaches meta-analysis or expert elicitation frameworks such as the Sheffield Elicitation Framework (SHELF).
O’Hagan et al. (2005) give an example of an assurance calculation for assessing the effect of a new drug in reducing C-reactive protein (CRP) in patients with rheumatoid arthritis.
“The outcome variable is a patient’s reduction in CRP after four weeks relative to baseline,
and the principal analysis will be a one-sided test of superiority at the 2.5%
significance level. The (two) population variance … is assumed to be … equal to
0.0625. … the test is required to have 80% power to detect a treatment effect of 0.2,
leading to a proposed trial size of n1 = n2 = 25 patients …"
For the calculation of assurance, we suppose that the elicitation of prior information … gives the mean of 0.2 and variance of 0.0625. If we assume a normal prior distribution, we can compute assurances with m = 0:2, v = 0.06 … With n = 25, we find assurance = 0.595.”
The calculation of sample size, and subsequently assurance, can be demonstrated easily in nQuery. The sample size calculation again used the “Two Sample Z-test” table.

This calculation shows that a sample size of 25 per group is needed to achieve power of 80%, for the given situation.
The assurance calculation can then be demonstrated using the “Bayesian Assurance for Two Group Test of Normal Means” table. To view the list of Bayesian Sample Size Procedures in nQuery, click here.
nQuery is the standard for fixed-term, Bayesian & Adaptive trials




